딥러닝 개요
인공지능, 머신러닝, 딥러닝
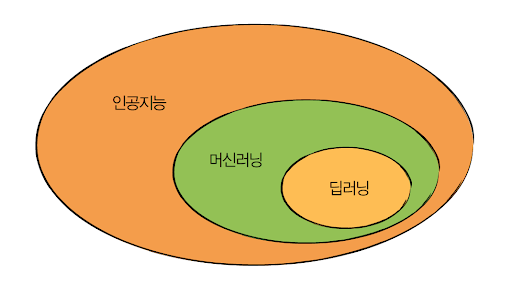
인공지능 (Artificial Intelligence, AI)
- 인공지능은 인간의 지능을 모방하여 만든 시스템 또는 기계를 의미합니다.
머신러닝 (Machine Learning, ML)
- 머신러닝은 인공지능의 한 분야로, 데이터를 기반으로 학습하는 알고리즘을 개발하는 방법론입니다.
- 머신러닝은 지도 학습, 비지도 학습, 강화 학습 등의 방법론을 포함합니다.
딥러닝 (Deep Learning, DL)
- 딥러닝은 머신러닝의 한 분야로, 인공 신경망(Artificial Neural Networks)을 사용하여 데이터를 학습하는 방법론입니다.
딥러닝이란?
- 딥러닝은 인공지능(AI)의 한 분야로, 인공신경망을 사용하여 데이터로부터 패턴을 학습하는 기술
- 머신러닝(Machine Learning)의 하위 분야 중 하나이며, 여러 층의 인공신경망을 사용하여 복잡한 패턴을 학습
- 대량의 데이터를 처리하고 분석하여 의미 있는 정보를 추출
활용 분야
- 이미지 분류 및 객체 감지: 이미지나 동영상에서 특정 객체를 인식하고 분류
- 자연어 처리: 텍스트 데이터를 이해하여 생성, 번역, 감정 분석, 챗봇 등의 작업 수행
- 음성 처리: 음성 데이터를 텍스트로 변환, 텍스트를 음성 데이터로 변환
딥러닝과 기존 프로그래밍의 차이
기존 프로그래밍 방식
- 개발자가 문제 해결을 위한 알고리즘을 설계하고 구현
- 명시적인 규칙과 로직을 기반으로 프로그램을 작성 -> if-else, for, while 등의 제어문 사용
- 복잡한 문제나 예외 상황에 대처하기 위해 개발자는 모든 경우를 고려하여 코드를 작성
- 새로운 문제나 변화에 대응하기 위해 프로그램을 수정 및 업데이트 필요
딥러닝의 특징과 장점
- 데이터로부터 패턴을 학습하여 문제를 해결
- 데이터를 기반으로 모델이 스스로 특징을 추출하고 학습
- 대량의 데이터를 활용할수록 모델의 성능이 향상되며, 복잡한 문제도 해결
- 학습된 모델은 새로운 입력 데이터에 대해 유연한 대처
데이터 중심
- 딥러닝은 데이터 중심(data-centric)의 접근법
- 알고리즘보다는 양질의 데이터 확보가 더 중요
- 대량의 데이터를 수집, 정제, 레이블링하는 과정이 필수적
- 데이터의 품질과 다양성이 모델의 성능에 직접적인 영향
딥러닝(머신러닝)의 분류
지도 학습 (Supervised Learning)
- 정답(레이블)이 있는 데이터를 사용하여 모델을 학습합니다.
- 모델은 입력과 정답 간의 관계를 학습하여 새로운 입력에 대해 예측을 합니다.
- 분류(Classification)와 회귀(Regression)가 있습니다.
- 이미지 분류, 스팸 메일 필터링, 주가 예측 등이 지도 학습의 예시입니다.
분류(Classification)
- 입력 데이터가 어떤 범주 또는 클래스에 속하는지 예측
- 예: 개, 고양이의 이미지 분류
- 훈련 데이터: 개 고양이의 영상과 정답(레이블 - 개, 고양이)
- 예측: 새로운 이미지가 개인지 고양이인지 분류
회귀(Regression)
- 입력 데이터를 바탕으로 연속적인 값을 예측
- 특정 클래스가 아닌 실수 값을 예측
- 예: 집 가격 예측
- 훈련 데이터: 집의 정보(면적, 위치, 시세 등)와 가격
- 예측: 새로운 집의 정보를 바탕으로 가격을 예측
비지도 학습 (Unsupervised Learning)
- 정답(레이블)이 없는 데이터를 사용하여 모델을 학습합니다.
- 데이터의 구조나 패턴을 스스로 발견합니다. 지도 학습과 달리 정해진 범주가 없습니다.
- 군집화(클러스터링 -Clustering), 차원 축소(Dimensionality Reduction), 이상치 탐지(Anomaly Detection) 등이 있습니다.
예: 고객 세분화
- 다양한 고객 데이터(구매 내역, 인구통계학적 정보, 행동 패턴 등)를 사용하여 유사한 특성을 가진 고객 그룹을 찾아냅니다.
- 찾아낸 고객 그룹에 따라 마케팅 전략을 수립하거나 맞춤형 서비스를 제공할 수 있습니다.
- 예: 마트의 기저귀를 사는 사람이 맥주도 많이 사는 경향이 있음
강화 학습 (Reinforcement Learning)
- 자신이 한 행동에 대해 보상을 받으며 학습합니다.
- 강화 학습은 에이전트(Agent)가 환경(Environment)과 상호작용하며 보상(Reward)을 최대화하는 방법을 학습합니다.
- 에이전트는 현재 상태(State)를 관찰하고, 행동(Action)을 선택하며, 선택한 행동에 따라 보상을 받습니다.
- 에이전트의 목표는 장기적인 관점에서 누적 보상을 최대화하는 최적의 정책(Policy)을 학습하는 것입니다.
- 강화 학습은 게임 AI, 로봇 제어, 자율 주행 등의 분야에서 활용됩니다.
- 알파고(AlphaGo)와 같은 바둑 AI가 강화 학습의 대표적인 예시입니다.
- https://www.youtube.com/watch?v=q3dN900QOtk
인공신경망 (Artificial Neural Network)
딥러닝은 인공 신경망(Artificial Neural Networks)을 사용하여 데이터를 학습합니다.
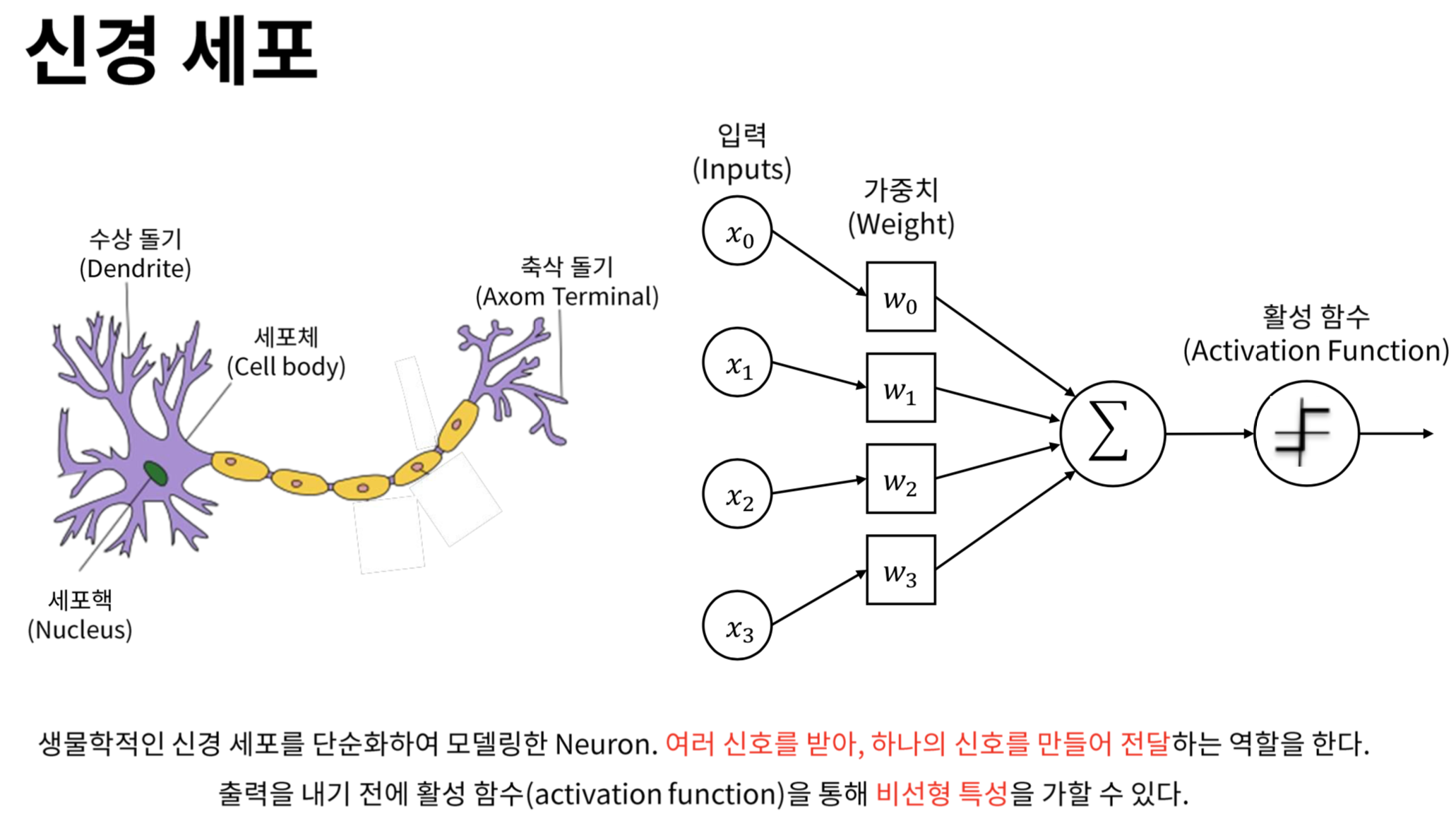
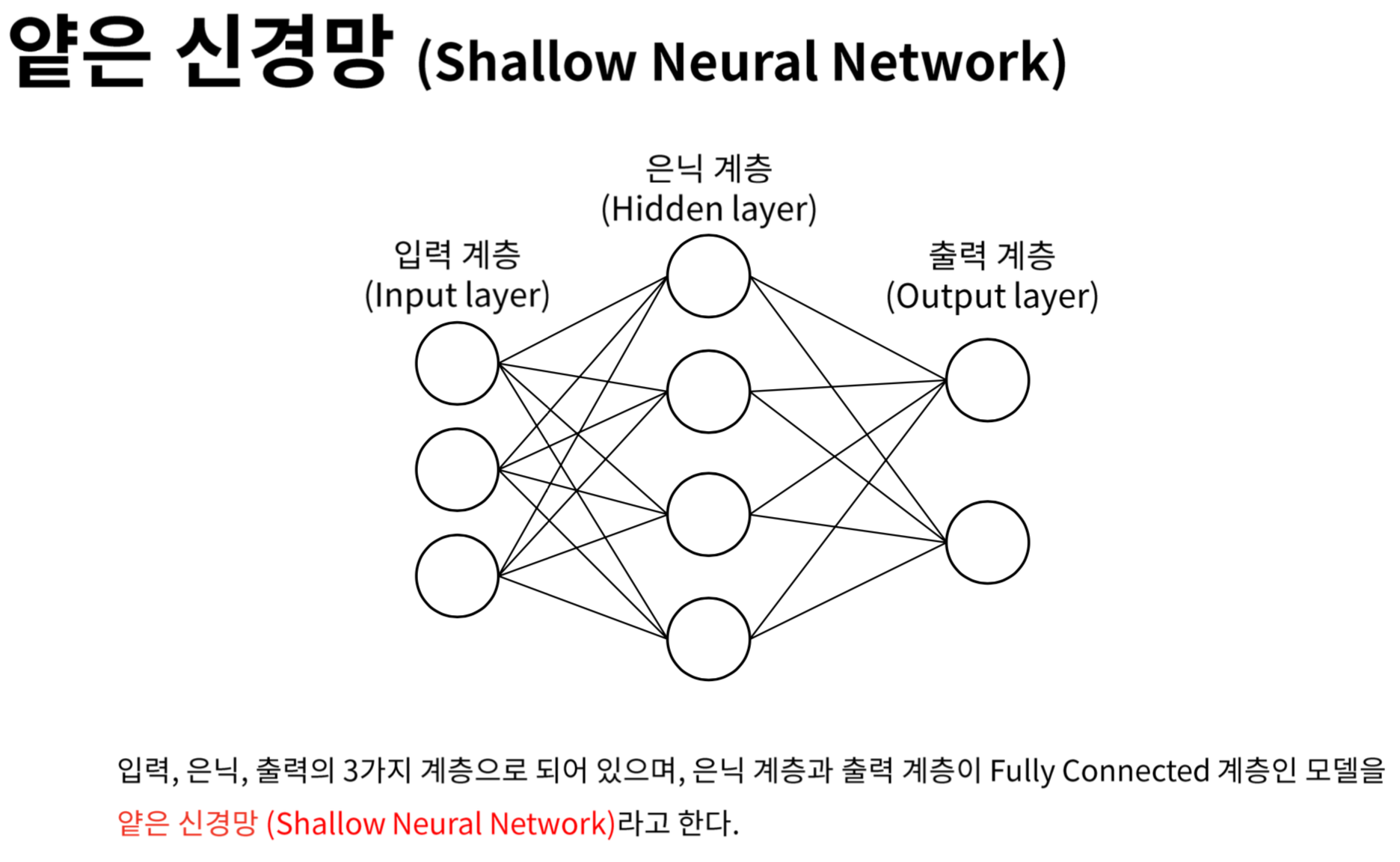
인공신경망의 구조
- 인공신경망은 생물학적 신경망에서 영감을 받아 고안된 머신러닝 모델입니다.
- 기본 구성 요소는 뉴런(노드)과 뉴런 간의 연결(가중치)입니다.
- 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 구성됩니다.
- 입력층은 데이터를 받아들이고, 은닉층에서 특징을 추출하며, 출력층에서 결과를 도출합니다.
- 각 층의 뉴런은 이전 층의 뉴런과 연결되어 있으며, 연결 강도는 가중치로 표현됩니다.
뉴런과 활성화 함수
- 뉴런(노드)은 인공신경망의 기본 처리 단위입니다.
- 각 뉴런은 입력 신호를 받아 가중합을 계산하고, 활성화 함수를 통해 출력 신호를 생성합니다.
- 활성화 함수는 뉴런의 출력을 결정하는 비선형 함수입니다.
- 활성화 함수를 통해 신경망은 비선형적인 문제를 해결할 수 있게 됩니다.
심층 신경망 (Deep Neural Networks)
- 심층 신경망은 여러 개의 은닉층을 가진 인공신경망을 말합니다.
- 은닉층의 개수가 증가할수록 신경망은 더 복잡한 특징을 추출할 수 있습니다.
- 각 은닉층은 이전 층의 출력을 입력으로 받아 더 추상화된 특징을 학습합니다.
학습이란?
학습의 개념
- 초기에 임의의 가중치(weight)와 편향(bias) 값을 설정하고 제공된 데이터에 해당하는 출력값을 도출
- 위의 출력 값과 정답값의 차이를 계산 - 손실 함수
- 출력값과 정답값의 차이를 최소화하는 방향으로 가중치와 편향을 조정 - 최적화 알고리즘(경사하강법)
학습 과정은 모델의 파라미터(가중치와 편향)를 조정하여 최적의 값을 찾아내는 과정입니다.
모델이란?
인공신경망의 구조와 최적의 값으로 조정된 가중치와 편향을 합쳐서 모델이라고 합니다.
손실 함수 (Loss Function)
- 손실 함수는 모델의 예측값과 실제 값 사이의 차이를 정량화하는 함수입니다.
- 손실 함수는 모델이 얼마나 잘 학습하고 있는지를 측정하는 기준으로 사용됩니다.
- 회귀 문제에서는 평균 제곱 오차(MSE) 등의 손실 함수를 사용하며, 분류 문제에서는 크로스 엔트로피(Cross-entropy) 손실 함수를 주로 사용합니다.
- 학습 과정에서는 손실 함수의 값을 최소화하는 방향으로 모델의 파라미터를 업데이트합니다.
최적화 알고리즘 (Optimization Algorithms)
- 최적화 알고리즘은 손실 함수를 최소화하기 위해 모델의 파라미터를 조정하는 방법입니다.
경사 하강법 (Gradient Descent)
- 가장 기본적인 최적화 알고리즘으로 손실 함수의 기울기(gradient)를 계산하여 기울기의 반대 방향으로 파라미터를 업데이트합니다.
- 손실 함수는 미분 가능해야 하며, 미분을 통해 기울기를 계산합니다.
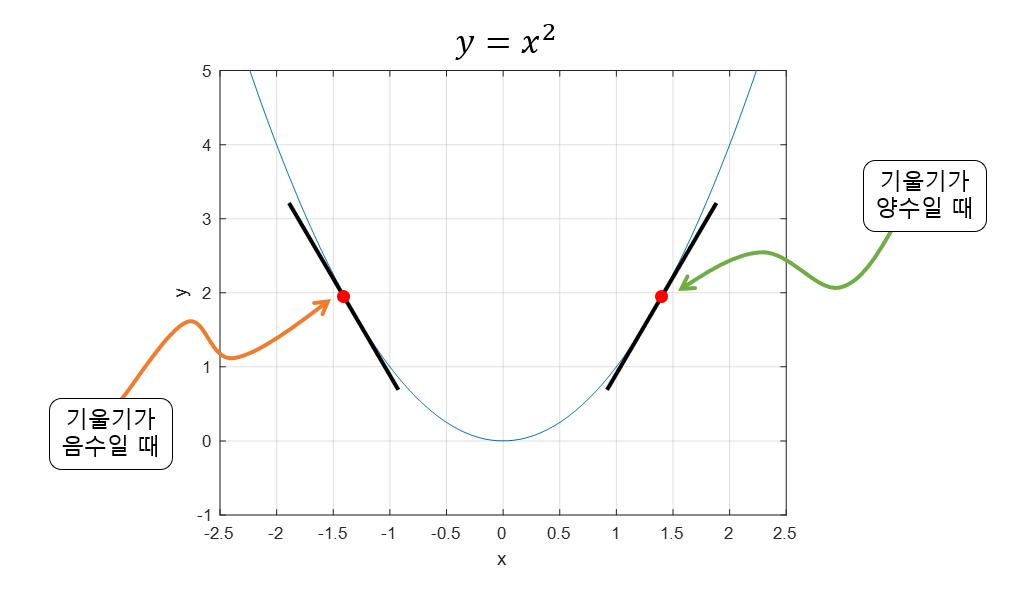
학습과정 시각화
https://playground.tensorflow.org/
역전파 (Backpropagation)
순전파란? (Forward Propagation)
순전파는 인공신경망에서 데이터가 입력층에서 출력층으로 전달되는 과정입니다.
- 입력 데이터가 입력층에 주어집니다.
- 입력과 가중치를 바탕으로 계산을 수행합니다.
- 계산 결과는 활성화 함수를 거쳐 다음 층으로 전달됩니다.
- 출력층에서 최종 출력을 도출합니다.
순전파는 학습된 모델로 새로운 데이터의 예측을 수행할 때에도 사용됩니다.
역전파란 (Backpropagation)
역전파는 순전파의 반대 과정으로, 모델이 예측한 출력과 실제 정답 사이의 오차를 이용하여 각 층의 가중치를 조정하는 방법입니다. 각 층의 가중치를 최적의 값으로 조정하기 위해 출력층에서 계산된 오차를 입력층 방향으로 전파하여 각 층의 가중치를 업데이트합니다.
- 순전파를 통해 예측 결과를 얻습니다.
- 예측 결과와 실제 정답 사이의 오차를 계산합니다.
- 오차를 출력층에서 입력층 방향으로 전파시킵니다.
- 각 층의 가중치에 대한 오차의 기여도를 계산합니다.
- 오차의 기여도를 바탕으로 가중치를 조정합니다.
- 이 과정을 반복하여 오차를 최소화하는 방향으로 가중치를 업데이트합니다.
기울기 (Gradient) 계산
- 기울기는 손실 함수를 가중치로 미분한 값으로, 가중치 업데이트 방향을 결정합니다.
- 역전파 단계에서는 연쇄 법칙(chain rule)을 이용하여 출력층부터 입력층까지 각 층의 그래디언트를 계산합니다.
가중치 업데이트
- 기울기가 계산되면 경사하강법(gradient descent)을 이용하여 가중치를 업데이트합니다.
- 가중치는 기울기의 반대 방향으로 일정 크기(학습률, learning rate)만큼 조정됩니다.
- 학습률이 너무 크면 수렴하지 않고 발산할 수 있으며, 너무 작으면 학습 속도가 느려질 수 있으므로 적절한 값을 선택해야 합니다.
필요성
이미지 인식, 자연어 처리 등은 아주 복잡한 문제이며 이러한 문제를 해결하기 위해서는 여러 층을 가진 깊은 신경망이 필요합니다. 깊은 신경망의 가중치를 학습시키기 위해서는 역전파 알고리즘이 필수적입니다.
과적합 (Overfitting)
과적합은 모델이 학습 데이터에 지나치게 적응하여 실제로는 존재하지 않는 패턴까지 학습하는 경우를 말합니다.
- 과적합된 모델은 학습 데이터에 대해서는 높은 성능을 보이지만, 새로운 데이터에 대해서는 일반화 성능이 떨어집니다.
- 과적합의 원인으로는 모델의 복잡도가 데이터의 복잡도에 비해 너무 높은 경우, 학습 데이터의 양이 부족한 경우 등이 있습니다.
일반화 (Generalization)
일반화는 모델이 학습 데이터뿐만 아니라 새로운 데이터에 대해서도 좋은 성능을 보이는 능력을 의미합니다.
- 일반화 성능이 좋은 모델은 실제 환경에서 더 유용하게 사용될 수 있습니다.
- 모델의 일반화 성능을 평가하기 위해서는 학습 데이터와는 별도의 검증 데이터와 테스트 데이터를 사용합니다.
일반화를 높이는 방법
- 편향되지 않은 더 많은 데이터를 사용 하여 모델을 학습합니다.
- 여러 가지의 규제화(Regularization) 기법을 사용하여 모델의 복잡도를 제어합니다.
- L1/L2 규제화: 손실 함수에 가중치의 절댓값(L1) 또는 제곱(L2)을 더해 가중치의 크기를 제한합니다.
- 드롭아웃(Dropout): 학습 중에 일부 뉴런(노드)을 무작위로 비활성화하여 모델의 과의존을 방지합니다.
- 조기 중단(Early Stopping): 검증 데이터의 성능이 더 이상 향상되지 않을 때 학습을 중단합니다.
딥러닝 프레임워크
TensorFlow
- 개발자: Google의 Brain 팀
- 특징: TensorFlow는 강력한 머신러닝 라이브러리로서, 데이터 플로우 그래프를 사용해 복잡한 신경망을 구축하고 훈련시킬 수 있습니다. 초보자가 사용 하기가 어렵습니다.
PyTorch
- 개발자: Facebook의 AI Research lab (FAIR)
- 특징: PyTorch는 동적 계산 그래프를 지원하여 모델을 유연하게 설계할 수 있습니다. Pythonic(Python 코딩 스타일)하고 사용자 친화적인 API를 제공합니다.
Keras
- 개발자: 프랑소와 숄레(François Chollet)
- 특징: Keras는 TensorFlow의 고수준 API로, 초보자도 쉽게 접근할 수 있도록 설계되었습니다. 초보자가 쉽고 빠르게 딥러닝 모델을 구축할 수 있습니다.
손실함수, 경상하강법 예제 코드
패키지 설치:
pip install numpy
pip install tensorflow
pip install torch torchvision torchaudio # windows, cpu 기준
Python 코드
# pip install numpy
import numpy as np
# 가상의 데이터 생성: y = 2x + 1 + 잡음
np.random.seed(0)
x = np.random.rand(100, 1) # 100개의 x 값
y = 2 * x + 1 + 0.1 * np.random.randn(100, 1) # y 값에 약간의 잡음 추가
# 모델의 매개변수 초기화
w = np.random.randn(1)
b = np.random.randn(1)
# 학습률과 반복 횟수 설정
learning_rate = 0.1
iterations = 300
# 손실 함수: 평균 제곱 오차(MSE)
def loss_function(x, y, w, b):
predictions = w * x + b
loss = np.mean((y - predictions) ** 2)
return loss
# 경사 하강법
for i in range(iterations):
predictions = w * x + b
loss = loss_function(x, y, w, b)
# 손실에 대한 w, b의 그래디언트 계산
w_grad = -2 * np.mean((y - predictions) * x)
b_grad = -2 * np.mean(y - predictions)
# 매개변수 업데이트
w -= learning_rate * w_grad
b -= learning_rate * b_grad
print(f"Iteration {i+1}: w = {w[0]}, b = {b[0]}, Loss = {loss}")
# 최종 모델 출력
print(f"Final model: y = {w[0]}x + {b[0]}")
new_x = np.random.rand(5, 1) # 5개의 새로운 x 값
actual_y = 2 * new_x + 1 # 실제 2x + 1 값 계산
new_predictions = w[0] * new_x + b[0]
print("New input x values:", new_x)
print("Actual y values (2x + 1):", actual_y)
print("Predicted y values:", new_predictions)
TensorFlow/Keras 코드
# pip install tensorflow
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
# 가상의 데이터 생성 (y = 2x + 1)
np.random.seed(0)
x = np.random.rand(100, 1) # 100개의 x 값
y = 2 * x + 1 + 0.1 * np.random.randn(100, 1) # y 값에 약간의 잡음 추가
# 모델 구성
model = Sequential()
model.add(Dense(1, input_dim=1, activation='linear')) # 선형 회귀이므로 활성화 함수는 선형(기본값)
# 모델 컴파일: 손실 함수 및 최적화 방법 설정
model.compile(optimizer=SGD(learning_rate=0.1), loss='mse')
# 모델 학습
model.fit(x, y, epochs=300)
# 최종 모델의 가중치와 편향 출력
weights, bias = model.layers[0].get_weights()
print(f"Learned weight: {weights[0][0]}, Learned bias: {bias[0]}")
# 새로운 데이터 5개 생성
new_x = np.random.rand(5, 1) # 5개의 새로운 x 값
new_y_actual = 2 * new_x + 1 # 새로운 데이터에 대한 실제 y 값 계산
# 새로운 데이터에 대한 예측 수행
new_predictions = model.predict(new_x)
# 출력
print("New input x values:", new_x.flatten()) # 새로운 입력값 출력
print("Actual y values:", new_y_actual.flatten()) # 새로운 입력에 대한 실제 y 값 출력
print("Predicted y values:", new_predictions.flatten()) # 예측된 y 값 출력
PyTorch 코드
# pip install torch torchvision torchaudio # windows, cpu 기준
import torch
import torch.nn as nn
import torch.optim as optim
# 데이터 생성
torch.manual_seed(0)
x = torch.rand(100, 1) # 100개의 x 값
y = 2 * x + 1 + 0.1 * torch.randn(100, 1) # y 값에 약간의 잡음 추가
# 모델 정의
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1) # 입력 차원 1, 출력 차원 1
def forward(self, x):
return self.linear(x)
# 모델 인스턴스 생성
model = LinearRegressionModel()
# 손실 함수 및 최적화기 정의
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 모델 훈련
epochs = 300
for epoch in range(epochs):
model.train()
optimizer.zero_grad() # 기울기 초기화
outputs = model(x)
loss = criterion(outputs, y)
loss.backward() # 역전파 실행
optimizer.step() # 매개변수 업데이트
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item()}")
# 최종 모델의 가중치와 편향 출력
final_weights = model.linear.weight.data
final_bias = model.linear.bias.data
print(f"Learned weight: {final_weights.item()}, Learned bias: {final_bias.item()}")
# 새로운 입력 데이터 생성 (예측을 위해)
new_x = torch.rand(5, 1) # 5개의 새로운 x 값
actual_y = 2 * new_x + 1 # 실제 2x + 1 값 계산
model.eval() # 모델을 평가 모드로 설정
with torch.no_grad(): # 그래디언트 계산 비활성화
new_predictions = model(new_x)
# 예측 결과 출력
print("New input x values:", new_x.numpy())
print("Actual y values (2x + 1):", actual_y.numpy())
print("Predicted y values:", new_predictions.numpy())
해시태그: #딥러닝 #인공지능 #머신러닝 #인공신경망 #학습 #역전파 #과적합 #텐서플로우 #파이토치 #케라스 #손실함수 #경사하강법 #예제코드
댓글남기기