Hugging Face - 01. Transformers - Pipelines
Transformer
공식문서: https://huggingface.co/docs/transformers/index
위의 공식 문서를 연습 한 곳: https://github.com/just-record/huggingface_practice
🤗 Transformers는 최신의 사전 훈련된 모델을 쉽게 다운로드하고 훈련할 수 있는 API와 도구를 제공합니다.
설치
pip install transformers, datasets, evaluate, accelerate
pip install torch # PyTorch
pip install tensorflow # TensorFlow
Pipeline
https://huggingface.co/docs/transformers/v4.44.0/en/main_classes/pipelines#transformers.pipeline
pipeline()은 Hub의 모든 모델을 언어, 컴퓨터 비전, 음성, 그리고 멀티모달 작업에 대한 추론을 쉽게 사용할 수 있게 해줍니다.
Task 지정
pipeline()를 생성 할 때 원하는 작업을 지정합니다. 이를 통해 해당 작업에 대한 모델을 사용할 수 있습니다.
# transformers의 pipeline를 import
from transformers import pipeline
# task를 지정하여 pipeline을 생성 - task는 text-classification
pipe = pipeline("text-classification")
# 생성된 pipeline의 객체인 pipe를 사용하여 text를 입력하여 모델을 실행
outs = pipe("This restaurant is awesome")
print(outs)
# 결과
[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
- task를 지정하여 pipeline을 생성할 수 있습니다.
- 이 때 모델은 task의 기본 모델을 사용합니다.
pipe.model을 통해 모델을 확인할 수 있습니다.
모델 지정
모델을 직접 지정하여 pipeline을 생성할 수 있습니다.
from transformers import pipeline
pipe = pipeline(model="FacebookAI/roberta-large-mnli")
outs = pipe("This restaurant is awesome")
print(outs)
# 결과
[{'label': 'NEUTRAL', 'score': 0.7313143014907837}]
# NEUTRAL(중립), CONTRADICTION(모순), ENTAILMENT(수반) 중 하나로 분류됨
- 모델을 직접 지정하여 pipeline을 생성할 수 있습니다.
- 지정 된 모델을 사용하여 작업을 수행합니다.
- https://huggingface.co/FacebookAI/roberta-large-mnli에서 위의 모델을 확인할 수 있습니다.
- NEUTRAL(중립), CONTRADICTION(모순), ENTAILMENT(수반) 중 하나로 분류됩니다.
- 2개의 문장이 입력되고 두 문장의 관계가 중립인지, 모순인지, 수반되는지를 분류합니다.
위 모델에 2개 문장을 입력
from transformers import pipeline
pipe = pipeline(model="FacebookAI/roberta-large-mnli")
outs = pipe("I like you. I love you")
print(outs)
outs = pipe("I like you. I hate you")
print(outs)
outs = pipe("I like you. I don't hate you")
print(outs)
# 결과
[{'label': 'NEUTRAL', 'score': 0.7160009145736694}]
[{'label': 'CONTRADICTION', 'score': 0.9992231130599976}]
[{'label': 'ENTAILMENT', 'score': 0.7354484796524048}]
- 2개의 문장을 입력하여 관계를 분류합니다.
I like you. I love you는 중립으로 분류됩니다.I like you. I hate you는 모순으로 분류됩니다.I like you. I don't hate you는 수반으로 분류됩니다.
다른 모델 사용
공식 문서의 예제가 아닌 다른 모델을 사용하여 pipeline을 생성합니다.
- https://huggingface.co/models?pipeline_tag=text-classification&sort=trending: model에서 ‘text-classification’으로 필터링 하여 목록을 확인합니다.
BAAI/bge-reranker-v2-m3=> https://huggingface.co/BAAI/bge-reranker-v2-m3: 임의 선택- 우측 상단 ‘Use in transformers’ 버튼 클릭 -> ‘Transformers’ -> ‘pipeline’이 있는 코드 복사
from transformers import pipeline
pipe = pipeline("text-classification", model="BAAI/bge-reranker-v2-m3")
outs = pipe("This restaurant is awesome")
print(outs)
######################################
### 2개의 문장: 문장간의 관련성을 분류
######################################
print('-'*30)
outs = pipe([{"text": "'what is panda?'", "text_pair": "The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China."}])
print(outs)
outs = pipe([{"text": "'what is panda?'", "text_pair": "hi"}])
print(outs)
# 결과
[{'label': 'LABEL_0', 'score': 0.1711844801902771}]
# LABEL_0(관련성이 낮음), LABEL_1(관련성이 높음) 중 하나로 분류됨
------------------------------
[{'label': 'LABEL_0', 'score': 0.9772558808326721}]
[{'label': 'LABEL_0', 'score': 0.00045623243204317987}]
다른 모델 사용 - 텍스트 감정 분석
- https://huggingface.co/models?pipeline_tag=text-classification&sort=trending
mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis=> https://huggingface.co/mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis- 우측 상단 ‘Use in transformers’ 버튼 클릭 -> ‘Transformers’ -> ‘pipeline’이 있는 코드 복사
from transformers import pipeline
pipe = pipeline("text-classification", model="mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis")
outs = pipe("This restaurant is awesome")
print(outs)
# positive, neutral, negative 중 하나로
######################################
### 위 문장의 결과가 예상 밖 -> 금융 데이터를 학습 한 모델이라서 그런 것으로 추정
# 모델 카드의 설명:
# This model is a fine-tuned version of distilroberta-base on the financial_phrasebank dataset. It achieves the following results on the evaluation set
# => 이 모델은 financial_phrasebank 데이터셋에 대해 미세 조정된 distilroberta-base의 버전입니다. 평가 세트에서 다음과 같은 결과를 얻었습니다:
######################################
print('-'*30)
outs = pipe("Operating profit totaled EUR 9.4 mn , down from EUR 11.7 mn in 2004 .")
print(outs)
# 결과
[{'label': 'neutral', 'score': 0.9986506104469299}]
------------------------------
[{'label': 'negative', 'score': 0.9987391829490662}]
2개 이상의 문장 입력
2개 이상의 문장을 list 형태로 입력하여 요청 할 수 있습니다.
from transformers import pipeline
pipe = pipeline("text-classification")
outs = pipe(["This restaurant is awesome", "This restaurant is awful"])
print(outs)
# 결과
[{'label': 'POSITIVE', 'score': 0.9998743534088135}, {'label': 'NEGATIVE', 'score': 0.9998743534088135}]
- 2개의 결과를 반환합니다.
Dataset 사용
Dataset을 입력으로 사용 할 수 있습니다.
Dataset - Iterator(yield 사용)
yield를 사용한 Iterator를 형태의 Dataset을 입력으로 사용할 수 있습니다.
from transformers import pipeline
# Iterator(yield 사용)를 사용한 Dataset 사용
def data():
for i in range(10):
yield f"My example {i}"
pipe = pipeline(model="openai-community/gpt2")
generated_characters = 0
for out in pipe(data()):
print(out[0]["generated_text"])
generated_characters += len(out[0]["generated_text"])
print(f"Generated {generated_characters} characters in total.")
# 결과
...
My example 8-bit console runs on Windows (x86_64). I also have 2-bit 64 bit OS's I use on my Mac (x86_64)!
My example 9th grade teacher works in a church. He's a big fan of Harry Potter, and he knows he's right. He's not going to let someone else decide who he feels like to make his life harder. He knows one girl
Generated 2013 characters in total.
Dataset - Hugging Face의 Datasets
Hugging Face의 Datasets을 사용하여 Dataset을 입력으로 사용할 수 있습니다.
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2")
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
# 결과
{'text': "EYB ZB COE C BEZCYCZ HO MOWWB EM BWOB ZMEG B COEB BE BEC B U OB BE BCB BEWUBB BXYWBESWYCB SBBB SSEZ C Z WH UB F IGVB SB Z<unk> XOES CZ BBXOXFBB OBY W B VM OFOWUONFWB ZCX B M WZ Q S C Q BC CQBF FOMB BOT ZWYBZ WB B CM B C B WZCWWW BHU EOYTO YWB BZ SHZBGEM Q OO T B BM XZ QW C OFBZMSEHB BE ZZBX M Q XB<unk> CEVWZ FOHSB W B O Z ZW S ZB O VM <s> D EUCKH XNC D Q BG B O BW U U MBE CBYE WB HFQUBQBUWZ B MW BMPY F ZBU EB B WBOF S XFOBB ZB X B MOT W B CEO WBM BBXBBEOBECB B UM C BP FMBWB BZ WFCED Z B B FXB Z OZ OBBZ NVD UBZC W B WYCWY X CE CW B WB MWU BWN B DECF GEF'C WZS CS BYWB<s>FZ'Z<s>ZGBU ECFEY BF ZOZ O UWBSSZBBBBW O O DBB BZWFUW ZWOZYCGOYCOT WC O CZ BD BBBBBBX X W T B BC BZC FWYBFO FBCE X Z PEZ CE B WEDBMBO BN B BY Y W B BMCB XOXQ BSZES Z M CF S FB BBXBB B C CSZ EF SEQF S BEC BNO BN SU EH WRFBS WB W B OEZ WS X B F B X ZBBE BBEHB B BU BECBSXHB BSQWFW BSZXH BWSEG W VQETZMCZ UCXW Z DBE<s> O SXZX MB W RX YYOBSUBWOCFYEF O B O B C Z UBEZBE BTB C CBFCB V W B BF W ZBBESBBECUT OH YCGZE W BYZBYGBEW BSBE B B CBEBEBU BU OQB OSB CB Z Z Z HZGTXZ USZFB FC ZO C"}
- 결과가 text로 나오지 않음
- hf-internal-testing/librispeech_asr_dummy이 모델 목록에서 검색 되지 않음
- hf-internal-testing 에서 test용 모델 인 듯
Dataset - Hugging Face의 Datasets - 다른 모델 사용
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="openai/whisper-large-v2")
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
# 결과
{'text': ' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.'}
{'text': " Nor is Mr. Quilter's manner less interesting than his matter."}
{'text': ' He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind.'}
{'text': " He has grave doubts whether Sir Frederick Leighton's work is really Greek after all, and can discover in it but little of Rocky Ithaca."}
{'text': " Linnell's pictures are a sort of up-guards-and-addams paintings, and Mason's exquisite idylls are as national as a jingo poem. Mr. Burkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap on the back, before he says, like a shampoo-er in a Turkish bath,"}
{'text': ' It is obviously unnecessary for us to point out how luminous these criticisms are, how delicate in expression.'}
{'text': ' On the general principles of art, Mr. Quilter writes with equal lucidity.'}
{'text': ' Painting, he tells us, is of a different quality to mathematics, and Finnish in art is adding more factor.'}
{'text': ' As for etchings, they are of two kinds, British and foreign.'}
{'text': ' He laments most bitterly the divorce that has been made between decorative art and what we usually call pictures, makes a customary appeal to the last judgment, and reminds us that in the great days of art Michelangelo was the furnishing upholsterer.'}
Dataset - Hugging Face의 Datasets - 다른 Dataset 사용
공식 문서의 예제가 아닌 다른 Dataset을 사용 해 보았습니다.
PolyAI/minds14- https://huggingface.co/docs/transformers/quicktour#pipeline
import torch
from transformers import pipeline
from datasets import load_dataset, Audio
speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", trust_remote_code=True)
dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
result = speech_recognizer(dataset[:4]["audio"])
print([d["text"] for d in result])
# 결과
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
Parameter
‘pipeline()’은 많은 매개변수를 지원합니다. 일부는 특정 작업에 관련되고, 일부는 모든 파이프라인에 공통적입니다. 일반적으로 원하는 곳 어디에서나 매개변수를 지정할 수 있습니다.
Device, batch_size
device- ‘0’: 첫번째 GPU, ‘1’: 두번째 GPU … ‘-1’: CPUdevice_map- 모델 가중치를 어떻게 로드하고 저장할지 자동으로 결정batch_size- 배치 크기- 기본적으로 pipeline은 배치 추론을 하지 않지만 사용 할 경우의 예시
from transformers import pipeline
##########################################
### 1. device=0 사용
# device=0: 첫번째 GPU 사용 - GPU가 없으면 오류 발생
# device=-1: CPU 사용
##########################################
pipe = pipeline(model="openai/whisper-large-v2", device=0)
# pipe = pipeline(model="openai/whisper-large-v2", device=-1)
response = pipe("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
print(response)
##########################################
### 2. device_map="auto" 사용 - 모델 가중치를 어떻게 로드하고 저장할지 자동으로 결정
# device_map="auto"를 사용 하면 'device=device'를 추가하지 않아도 됨
##########################################
print('-'*30)
# pipe = pipeline(model="openai/whisper-large-v2", device_map="auto", low_cpu_mem_usage=True)
pipe = pipeline(model="openai/whisper-large-v2", device_map="auto")
response = pipe("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
print(response)
##########################################
### 3. batch_size 사용 - 한 번에 처리할 음성 파일의 개수
# batch_size=2: 오류 발생 - IndexError: tuple index out of range => 원인을 찾아야 함
# batch_size=1: 정상 처리
##########################################
print('-'*30)
# pipe = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
pipe = pipeline(model="openai/whisper-large-v2", device=0, batch_size=1)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = pipe(audio_filenames)
print(texts)
# 결과
[{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}]
------------------------------
[{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}]
------------------------------
[{'text': ' He hoped there would be stew for dinner, turnips and carrots and bruised potatoes and fat mutton pieces to be ladled out in thick, peppered, flour-fattened sauce.'}, {'text': ' Stuff it into you, his belly counselled him.'}, {'text': ' After early nightfall the yellow lamps would light up here and there the squalid quarter of the brothels.'}, {'text': ' Y en las ramas medio sumergidas revoloteaban algunos pájaros de quimérico y legendario plumaje.'}]
Parameter - Task에 따른 Parameter
from transformers import pipeline
##########################################
### 'return_timestamps' - 발음된 시간
##########################################
# pipe = pipeline(model="openai/whisper-large-v2", device=0, return_timestamps=True)
pipe = pipeline(model="openai/whisper-large-v2", device=-1, return_timestamps=True)
response = pipe("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
print(response)
# {'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
##########################################
### 'chunk_length_s' - 긴 오디오 파일을 작은 청크(chunk)로 나누며 각 청크의 길이를 초 단위로 지정
##########################################
print('-'*30)
# pipe = pipeline(model="openai/whisper-large-v2", device=0, chunk_length_s=30)
pipe = pipeline(model="openai/whisper-large-v2", device=-1, chunk_length_s=30)
response = pipe("https://huggingface.co/datasets/reach-vb/random-audios/resolve/main/ted_60.wav")
print(response)
# {'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"}
# 결과
[{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}]
------------------------------
[{'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"}]
에러 발생
# ValueError: ffmpeg was not found but is required to load audio files from filename
# 위와 같은 에러가 발생하면 ffmpeg를 설치해야 합니다.
sudo apt update
sudo apt install ffmpeg
지원 되는 Tasks
소스 코드를 참조하면 다음과 같은 task들을 지원하는 걸 확인할 수 있습니다.
https://github.com/huggingface/transformers/blob/v4.43.3/src/transformers/pipelines/__init__.py#L552
"audio-classification": will return a [AudioClassificationPipeline]."automatic-speech-recognition": will return a [AutomaticSpeechRecognitionPipeline]."depth-estimation": will return a [DepthEstimationPipeline]."document-question-answering": will return a [DocumentQuestionAnsweringPipeline]."feature-extraction": will return a [FeatureExtractionPipeline]."fill-mask": will return a [FillMaskPipeline]:."image-classification": will return a [ImageClassificationPipeline]."image-feature-extraction": will return an [ImageFeatureExtractionPipeline]."image-segmentation": will return a [ImageSegmentationPipeline]."image-to-image": will return a [ImageToImagePipeline]."image-to-text": will return a [ImageToTextPipeline]."mask-generation": will return a [MaskGenerationPipeline]."object-detection": will return a [ObjectDetectionPipeline]."question-answering": will return a [QuestionAnsweringPipeline]."summarization": will return a [SummarizationPipeline]."table-question-answering": will return a [TableQuestionAnsweringPipeline]."text2text-generation": will return a [Text2TextGenerationPipeline]."text-classification"(alias"sentiment-analysis"available): will return a [TextClassificationPipeline]."text-generation": will return a [TextGenerationPipeline]:."text-to-audio"(alias"text-to-speech"available): will return a [TextToAudioPipeline]:."token-classification"(alias"ner"available): will return a [TokenClassificationPipeline]."translation": will return a [TranslationPipeline]."translation_xx_to_yy": will return a [TranslationPipeline]."video-classification": will return a [VideoClassificationPipeline]."visual-question-answering": will return a [VisualQuestionAnsweringPipeline]."zero-shot-classification": will return a [ZeroShotClassificationPipeline]."zero-shot-image-classification": will return a [ZeroShotImageClassificationPipeline]."zero-shot-audio-classification": will return a [ZeroShotAudioClassificationPipeline]."zero-shot-object-detection": will return a [ZeroShotObjectDetectionPipeline].
Vision, Audio, Multimodal
Vision, Audio, Multimodal 형태의 Pipeline도 지원 하면 사용 방법은 거의 동일합니다.
Vision Pipeline
from transformers import pipeline
vision_classifier = pipeline(model="google/vit-base-patch16-224", device=0)
preds = vision_classifier(
images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
print(preds)
# 결과
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
Audio Pipeline
from transformers import pipeline
transcriber = pipeline(task="automatic-speech-recognition")
response = transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
print(response)
# 결과
[{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}]
Multimodal Pipeline
# 설치 필요
sudo apt install -y tesseract-ocr
pip install pytesseract
from transformers import pipeline
vqa = pipeline(model="impira/layoutlm-document-qa", device=0)
output = vqa(
image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
question="What is the invoice number?",
)
output[0]["score"] = round(output[0]["score"], 3)
print(output[0]["score"])
# 결과
[{'answer': 'INV-123', 'score': 0.999}]
Large Model - with accelerate
Hugging Face의 accelerate 라이브러리를 사용하면 대규모 모델을 쉽게 실행할 수 있습니다.
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
print(output)
# 결과
[{'generated_text': 'This is a cool example! How did you get a pic of the front of it?'}]
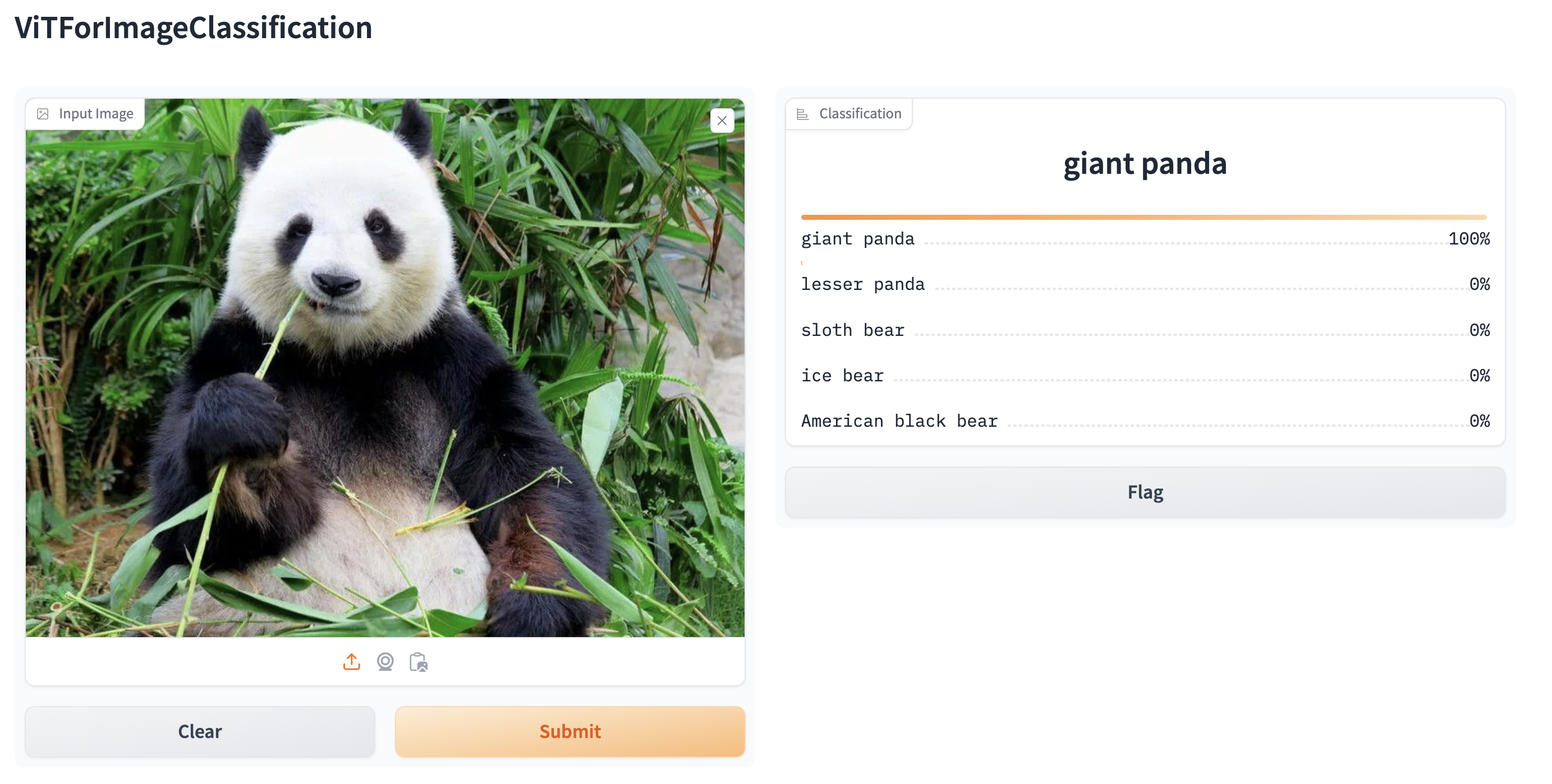
Gradio로 웹서버 구동
pip install gradio
from transformers import pipeline
import gradio as gr
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
gr.Interface.from_pipeline(pipe).launch()
http://127.0.0.1:7860 - 웹 브라우저에서 접속
Text Generation
지금 까지 학습 한 내용을 바탕으로 최근 모델의 Text Generation을 실행해 보았습니다.
- 모델:
meta-llama/Meta-Llama-3.1-8B-Instruct - 모델 사용 시 인증 필요
- Hugging Face의 Access Token 필요
모델
https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct
모델 사용 시 인증 필요
- 입력 항목: ‘First Name’, ‘Last Name’, ‘Data of birth’, ‘Country’, ‘Affitiation’, ‘Job title’
- ‘라이선스 동의’, ‘개인정보 처리 동의’
- 모델 소유자의 승인 대기 -> 승인 -> 모델 사용 가능
Hugging Face의 Access Token 필요
- 로그인 -> ‘Profile’(우측 상단) -> ‘Settings’ -> ‘Access Tokens’ -> ‘+Create new token’
- Token type: Write, Token name: xxx -> ‘Create token’ -> Copy
코드
from dotenv import load_dotenv
load_dotenv()
from huggingface_hub import login
import os
result = login(token=os.environ['HUGGING_FACE_HUB_TOKEN'])
print(result)
from transformers import pipeline
messages = [
{"role": "user", "content": "Who are you?"},
]
pipe = pipeline("text-generation", model="meta-llama/Meta-Llama-3.1-8B-Instruct", device=0)
outs = pipe(messages)
print(outs)
# 결과
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 224.00 MiB. GPU 0 has a total capacity of 23.68 GiB of which 119.06 MiB is free. Including non-PyTorch memory, this process has 23.49 GiB memory in use. Of the allocated memory 23.24 GiB is allocated by PyTorch, and 1.17 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
- CUDA out of memory 에러 발생
- 최근 모델은 실패 했지만 시간을 두고 다른 모델 도전 또는 메모리 문제를 해결 시도
해시태그: #Hugging-Face #Transformers #Pipelines #Task #Model #Dataset #Parameter #Device #batch_size #Vision #Audio #Multimodal #Text-Generation #Gradio
댓글남기기